Last night, I decided to bite the bullet and add yet another method to implement models in DNest4, this time using R. Statisticians know R, so it’s probably a good idea to support their language in some form. This brings the list of ways of using DNest4 to the following:
-
- Write C++ model classes (recommended, fastest, etc), as described in the paper
- Write Python model classes (also in the paper)
- Use the Python-based modelling language to specify your model, which is then translated into C++ model classes automatically (though they are not as optimised as they would be if you wrote them yourself)
- Write an R file specifying your model.
Running an instance of R inside C++ is fairly easy to do thanks to RInside, but do not expect it to compete with pure C++ for speed, unless your R likelihood function is heavily optimised and dominates the computational cost so that overheads are irrelevant. That’s not the case in the example I implemented yesterday.
This post contains instructions to get everything up and running and to implement models in R. Since I’m not very good at R, some of this is probably more complicated than it needs to be. I’m open to suggestions.
Install DNest4
First, git clone and install DNest4 by following along with my quick start video. Get acquainted with how to run the sampler and what the output looks like.
Look at the R model code
Then, navigate to DNest4/code/Templates/RModel to see the example of a model implemented in R. There’s only one R file in that directory, so open it and take a look. There are three key parts of it. The variable num_params is the integer number of parameters in the model. These are assumed to have Uniform(0, 1) priors, but the function from_uniform is used to apply transformations to make the priors whatever you want them to be. The example is a simple linear regression with two vague normal priors and one vague log-uniform prior. It’s the same example from the paper. Then there’s the log likelihood, which is probably the easiest part to understand. I’m using the traditional iid gaussian prior for the noise around the regression line, with unknown standard deviation.
Fiddly library stuff
Make sure the R packages Rcpp and RInside are installed. In R, do this to install them:
> install.packages("Rcpp")
> install.packages("RInside")
Once this is done, find where the header files R.h, Rcpp.h, and RInside.h are on your system, and put those paths on the appropriate lines in DNest4/code/Templates/RModel/Makefile. Then, find the library files libR.so and libRInside.so (the extension is probably different on a Mac) and put their paths in the Makefile as well as adding them to your LD_LIBRARY_PATH environment variable. Enjoy the 1990s computing nostalgia.
Compile
Run make in order to compile the example, then execute main in order to run it. Everything should run just the same as in my quick start video, except slower. Don’t try to use multiple threads, and enjoy writing models in R!

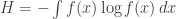
 is not invariant under changes of coordinates. When using this quantity, a notion of volume is implicitly brought in, based on a flat measure that would not remain flat under arbitrary coordinate changes. In principle, you should give the measure explicitly (or use relative entropy/KL divergence instead), but it’s no big deal if you don’t, as long as you know what you’re doing.
is not invariant under changes of coordinates. When using this quantity, a notion of volume is implicitly brought in, based on a flat measure that would not remain flat under arbitrary coordinate changes. In principle, you should give the measure explicitly (or use relative entropy/KL divergence instead), but it’s no big deal if you don’t, as long as you know what you’re doing. , because if you do a nonlinear transformation the area will change.” On second thoughts, many maths Wikipedia pages do degenerate into fibre bundles rather quickly, so maybe I shouldn’t say nobody would be tempted.
, because if you do a nonlinear transformation the area will change.” On second thoughts, many maths Wikipedia pages do degenerate into fibre bundles rather quickly, so maybe I shouldn’t say nobody would be tempted.