
The “evidence” or “marginal likelihood” integral, 
However, there are other integrals that Bayesians need to do that are orders of magnitude harder than this. Suppose I want to measure some parameters 


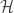
![\mathcal{H} = \int p(\theta | x) \log\left[\frac{p(\theta | x)}{p(\theta)}\right] \, d\theta](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BH%7D+%3D+%5Cint+p%28%5Ctheta+%7C+x%29+%5Clog%5Cleft%5B%5Cfrac%7Bp%28%5Ctheta+%7C+x%29%7D%7Bp%28%5Ctheta%29%7D%5Cright%5D+%5C%2C+d%5Ctheta&bg=ffffff&fg=333333&s=0&c=20201002)
Remembering that we have nuisance parameters, the posterior and prior in this expression may be written as marginalisations of the joint posterior/prior of
![\mathcal{H} = \int \left(\int p(\eta, \theta | x)\, d\eta\right) \log\left[\frac{\left(\int p(\eta, \theta | x) \, d\eta\right)}{\left(\int p(\eta, \theta)\,d\eta \right)}\right] \, d\theta](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BH%7D+%3D+%5Cint+%5Cleft%28%5Cint+p%28%5Ceta%2C+%5Ctheta+%7C+x%29%5C%2C+d%5Ceta%5Cright%29+%5Clog%5Cleft%5B%5Cfrac%7B%5Cleft%28%5Cint+p%28%5Ceta%2C+%5Ctheta+%7C+x%29+%5C%2C+d%5Ceta%5Cright%29%7D%7B%5Cleft%28%5Cint+p%28%5Ceta%2C+%5Ctheta%29%5C%2Cd%5Ceta+%5Cright%29%7D%5Cright%5D+%5C%2C+d%5Ctheta&bg=ffffff&fg=333333&s=0&c=20201002)
That’s how much information the data provided to us about the parameters of interest. Before we get the data, we might be interested in knowing the expected amount of information we will get, 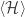
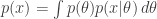
![\left<\mathcal{H}\right>= \int p(x) \int \left(\int p(\eta, \theta | x)\, d\eta\right) \log\left[\frac{\left(\int p(\eta, \theta | x) \, d\eta\right)}{\left(\int p(\eta, \theta)\,d\eta \right)}\right] \, d\theta \, dx](https://s0.wp.com/latex.php?latex=%5Cleft%3C%5Cmathcal%7BH%7D%5Cright%3E%3D+%5Cint+p%28x%29+%5Cint+%5Cleft%28%5Cint+p%28%5Ceta%2C+%5Ctheta+%7C+x%29%5C%2C+d%5Ceta%5Cright%29+%5Clog%5Cleft%5B%5Cfrac%7B%5Cleft%28%5Cint+p%28%5Ceta%2C+%5Ctheta+%7C+x%29+%5C%2C+d%5Ceta%5Cright%29%7D%7B%5Cleft%28%5Cint+p%28%5Ceta%2C+%5Ctheta%29%5C%2Cd%5Ceta+%5Cright%29%7D%5Cright%5D+%5C%2C+d%5Ctheta+%5C%2C+dx&bg=ffffff&fg=333333&s=0&c=20201002)
We can use this to do experimental design: it makes sense to choose your experiment to optimise the expected amount of information you’ll get about the parameters of interest. This wraps an optimisation problem around the above expression too.
In summary, the evidence is not a hard integral. We know how to do it. Other useful integrals, not so much.

Pingback: Brendon Brewer on “Hard Integrals” | Hypergeometric